




GraphQL can be really helpful in many ways if used properly, which in fact can be generalized for a lot of “frameworks” out there. We also learned a few things during our journey of working with GraphQL. Before we begin, we at braincuber use apollo-client and apollo-express-server. So let’s dig in.
1. Use Dataloader extensively
DataLoader is a small caching and batching library which helps in caching similar API calls as well as batch API calls for better performance of queries at the resolver level. Dataloader basically solves a widely known issue called the “N+1” problem. This will come in really handy as your graph starts to grow bigger and bigger, both in terms of size and the levels of nesting.
We won’t go into the details of this problem in detail, but if you’re interested in understanding it here’s the link to another article we did on DataLoader.
2. DRY, really?
The DRY principle is all cool, but sometimes it can come back to bite you. In GraphQL, the dry principle can be incorporated using fragments.
Fragments are nothing but chunks of queries that can be re-used in multiple queries. Here’s an example:
export const USER_FRAGMENT = gql`
fragment UserFields on User {
id
createdOn
dob
status
name {
first
last
salutation
}
gender
homeCity
anniversary
languagePreference
loyaltyDetails {
balance
type
membershipLevel
membershipNumber
programeName
}
}
`;
The above code represents a fragment of type User which can be used in multiple queries which might need to fetch data related to a user. Upon following this pattern we write the required data graph once and re-use it in multiple queries as per the requirement. Very neat, isn’t it? Not really. This does help in maintaining the concept of “re-usability” of code but can start creating problems as the code base grows. Let’s understand this with an example.
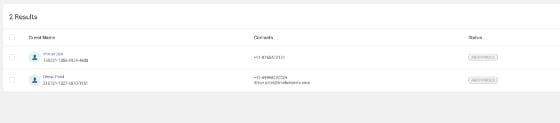
The above page is the user search results page from an internal dashboard, on this page we show user information such as name, id, contacts, a status which we typically get in one single API call which will be resolved to type User and one might be tempted to use the above fragment which is already written, right? But if you see that fragment again, it also fetches Loyalty Details, which probably would be another API call on the GraphQL Server. This sounds like an “Over-fetching” problem, which is weird because that is what GraphQL is supposed to solve, right?
This is a coding pattern concern to be very honest, it is fine to give up on code reusability (DRY principle)where it causes more damage than good. Another way of solving this is to use inline fragments along with a directive called Include.
Here is a small example of what it might look like:
... on User {
id
createdOn
dob
status
name {
first
last
salutation
}
gender
homeCity
anniversary
languagePreference
loyaltyDetails @include(if: $includeLoyaltyDetails){
balance
type
membershipLevel
membershipNumber
programeName
}
}
}
In the above snippet, we have an inline fragment on type User which will fetch loyalty details on if includeLoyaltyDetails is marked true.
3. Caching can be a frenemy
Apollo client (one of the many GraphQL providers) provides in-memory caching of results of queries that are fired in a particular session. It doesn’t persist across the session though, this can still be very helpful in boosting performance for the users.
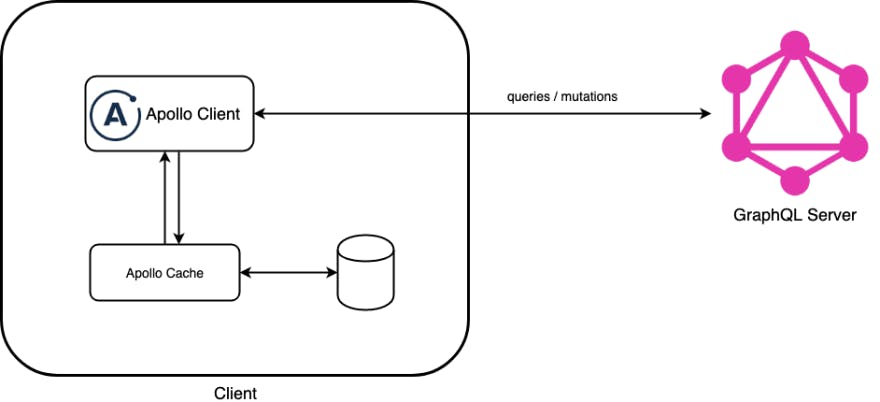
As seen in the image above, depending on how you have configured your client it will either check the cache first to see if it contains the data you are looking for, or it will ask the server and then tell the cache about the result.
Quite useful, isn’t it? But things can go terribly wrong if for some reason you provide the same ID for a given type name of a schema. In this case, what happens is data no more will be reliable, and you might see data repetition because of clashing ids alongside one particular type name.
Consider this snippet of User data which we fetch using a query searchUser. This is a basic query that returns a list of users depending upon various query parameters passed to it. This searchUser query resolves to type of [User] .
{
"id": "150521-1356-8924-4600",
"createdOn": "2021-05-15T13:56:00.718004Z",
"dob": "1092-04-12",
"status": "anon",
"name": {
"first": "dhruvv",
"last": "patel",
"__typename": "PersonName"
},
"gender": "male",
"homeCity": null,
"anniversary": "1092-04-12",
"nationality": "Indian",
"languagePreference": "English",
"__typename": "User",
"contacts": [
{
"id": "150521-1356-8924-4600|1",
"value": "8765432131",
"type": "phone",
"isVerified": false,
"isPrimaryContact": true,
"isWhatsappOptedIn": true,
"countryCode": "+91",
"__typename": "UserContact"
}
]
If you look at this response which is returned by the GraphQL server to the client, you’ll notice that in the contacts array we have a field id which is a combination of userId | id , why is this necessary?
As we discussed earlier that client-side caching depends upon the id and the typename of the given schema. In this case, if we use the id directly provided by API response which is of type INT along with __typename”: UserContact , all the users which will be returned to the client-side as a response to searchUser query will have the same contact number as that of the very first user in the list.
The above issue is something that I particularly faced while developing a new internal User data dashboard and was fairly new to GraphQL. It took me days to figure out what magic was causing the contacts to be the same as the first user.
4. Understand the Domain
This part is very important when it comes to structuring your schemas and data sources. You really need to have domain-level knowledge about the problem you are working on in order to write a really neat Schema. In a way, your schemas can be a way to understand how actually everything works around. A lot depends upon how you model your schemas, there should be a clear understanding of what can be an entity and what can probably be an attribute. This becomes easier in case the GraphQL layer acts as a data aggregator layer because you can then rely on the microservice side schemas to a certain extent.
5. Be intentional nullability
“Nullability” is kind of important for the users indirectly because they might not know what that is exactly but it does help in improving the user experience of the application. Unlike REST API, where you don’t always know what kind of response would be returned upon calling a certain endpoint, GraphQL allows you to decide a complete schema to which your response would be mapped and also provide the flexibility of deciding if a value is required in return or not. Let’s again look at one example because that’s how it goes here.
extend type Query {
hotelById(id: ID!): Hotel!
}
Let’s take a look at this small looking query here, ! the sign next to anything here means that field is non-nullable. By using this nullability check here you can make use of the concept called “Error Boundaries” which allows you to gracefully handle any mishaps happening on the client-side as GraphQl itself if throw an error instead of your code breaking in production which is we all know a nightmare!
GraphQL has been an integral part of braincuber's tech stack since mid-2019. It is being extensively used to power braincuber's new SaaS vertical Hotel Superhero as well as a few important pages like the search results page in braincuber's desktop site and booking history page in the mobile app.
All these points mentioned above are very simple at face value, but they are very important when it comes to developing a solid base for any codebase. There are still a lot of things to cover such as the Security aspect of Queries/Mutations, nesting problems as the graph grows in size along with the business, etc but those are some topics that can be justified only if talked about separately. This article was about what we as a team learned from the mistakes we did ourselves.
Hiring
We’re hiring! 🎊 If what we do excites you, we are actively hiring for our engineering team at braincuber.com In case you are someone who wants to work on some really exciting issues and probably brag about solving them, come join us. You can reach out to me on Twitter or you can visit our careers website as well to look out for open roles.